(換膚)
語(yǔ)言:

 HDFS 替代方案:比較優(yōu)勢(shì)和劣勢(shì) (hdfs替代方案)
HDFS 替代方案:比較優(yōu)勢(shì)和劣勢(shì) (hdfs替代方案)
簡(jiǎn)介Hadoop分布式文件系統(tǒng),HDFS,是一種流行的大數(shù)據(jù)文件系統(tǒng),用于存儲(chǔ)和管理海量數(shù)據(jù)集,隨著大數(shù)據(jù)技術(shù)的不斷發(fā)展,出現(xiàn)了許多替代HDFS的解決方案,提供不同的優(yōu)勢(shì)和劣勢(shì),本文將比較幾種主流的HDFS替代方案,包括,CephGlusterFSLustreMinIOTachyon比較因素在比較HDFS替代方案時(shí),需要考慮以下因素,...。
互聯(lián)網(wǎng)資訊 2024-10-01 00:40:40
 HDFS 在大數(shù)據(jù)分析中的應(yīng)用:存儲(chǔ)和處理考慮因素 (hdfs datanode)
HDFS 在大數(shù)據(jù)分析中的應(yīng)用:存儲(chǔ)和處理考慮因素 (hdfs datanode)
Hadoop分布式文件系統(tǒng),HDFS,是一種分布式文件系統(tǒng),專為存儲(chǔ)和處理大數(shù)據(jù)而設(shè)計(jì),在本文中,我們將探討HDFS在大數(shù)據(jù)分析中的應(yīng)用及其與存儲(chǔ)和處理相關(guān)的考慮因素,HDFS的特點(diǎn)分布式存儲(chǔ),HDFS將數(shù)據(jù)存儲(chǔ)在多個(gè)分布式服務(wù)器上,這提高了可用性和容錯(cuò)性,大數(shù)據(jù)處理,HDFS能夠處理海量數(shù)據(jù)集,而無(wú)需擔(dān)心存儲(chǔ)空間或處理能力限制,高吞...。
技術(shù)教程 2024-10-01 00:34:43
 HDFS 和云計(jì)算:集成和用例 (hdfs云盤(pán))
HDFS 和云計(jì)算:集成和用例 (hdfs云盤(pán))
簡(jiǎn)介HDFS,Hadoop分布式文件系統(tǒng),是一個(gè)分布式文件系統(tǒng),最初由ApacheHadoop項(xiàng)目開(kāi)發(fā),它旨在在商品硬件集群上存儲(chǔ)大規(guī)模數(shù)據(jù),并提供高吞吐量和容錯(cuò)性,云計(jì)算提供了一種通過(guò)互聯(lián)網(wǎng)訪問(wèn)共享計(jì)算資源的方式,它使企業(yè)能夠按需擴(kuò)展和縮減其IT基礎(chǔ)設(shè)施,并專注于其核心業(yè)務(wù),HDFS與云計(jì)算的集成可以為企業(yè)帶來(lái)許多好處,包括,按需可...。
技術(shù)教程 2024-10-01 00:32:33
 優(yōu)化 HDFS 性能:配置、調(diào)優(yōu)和故障排除 (優(yōu)化HDR場(chǎng)景下部分顯示問(wèn)題)
優(yōu)化 HDFS 性能:配置、調(diào)優(yōu)和故障排除 (優(yōu)化HDR場(chǎng)景下部分顯示問(wèn)題)
Hadoop分布式文件系統(tǒng),HDFS,是一個(gè)可擴(kuò)展、高度可靠的分布式存儲(chǔ)系統(tǒng),用于處理和存儲(chǔ)海量數(shù)據(jù)集,為了充分利用HDFS的潛力,優(yōu)化其性能至關(guān)重要,本文將探討配置、調(diào)優(yōu)和故障排除技術(shù),以幫助您優(yōu)化HDFS性能,配置優(yōu)化優(yōu)化NameNode配置,調(diào)整NameNode內(nèi)存,dfs.namenode.heapsize,、Java進(jìn)程最大...。
本站公告 2024-10-01 00:29:35
 Hadoop 生態(tài)系統(tǒng)中的 HDFS:與其他組件的交互 (hadoop是什么)
Hadoop 生態(tài)系統(tǒng)中的 HDFS:與其他組件的交互 (hadoop是什么)
簡(jiǎn)介Hadoop分布式文件系統(tǒng),HDFS,是Hadoop生態(tài)系統(tǒng)中的一個(gè)核心組件,它是一個(gè)分布式文件存儲(chǔ)系統(tǒng),用于在Hadoop集群中存儲(chǔ)和管理海量數(shù)據(jù),HDFS旨在高度容錯(cuò)、可擴(kuò)展和可靠,使其成為處理大型數(shù)據(jù)集的理想解決方案,HDFS的工作原理HDFS由兩個(gè)主要組件組成,NameNode和DataNode,NameNode是HDFS...。
技術(shù)教程 2024-10-01 00:26:51
 使用 HDFS 管理巨量數(shù)據(jù)集:最佳實(shí)踐和提示 (使用hdfs命令創(chuàng)建文件夾)
使用 HDFS 管理巨量數(shù)據(jù)集:最佳實(shí)踐和提示 (使用hdfs命令創(chuàng)建文件夾)
簡(jiǎn)介ApacheHadoop分布式文件系統(tǒng),HDFS,是一種分布式文件系統(tǒng),專為管理和處理大數(shù)據(jù)量而設(shè)計(jì),它將文件存儲(chǔ)在許多計(jì)算節(jié)點(diǎn)上,并使用主節(jié)點(diǎn)來(lái)協(xié)調(diào)訪問(wèn),HDFS非常適合存儲(chǔ)和處理大量非結(jié)構(gòu)化數(shù)據(jù),例如日志文件、傳感器數(shù)據(jù)和社交媒體數(shù)據(jù),它還被廣泛用于云計(jì)算和機(jī)器學(xué)習(xí)等應(yīng)用,使用HDFS的最佳實(shí)踐以下是一些使用HDFS管理巨量數(shù)...。
最新資訊 2024-10-01 00:21:32
 深入了解 HDFS:架構(gòu)、優(yōu)點(diǎn)和缺點(diǎn) (深入了解后面句子是什么)
深入了解 HDFS:架構(gòu)、優(yōu)點(diǎn)和缺點(diǎn) (深入了解后面句子是什么)
簡(jiǎn)介Hadoop分布式文件系統(tǒng),HDFS,是一個(gè)分布式文件系統(tǒng),旨在為大數(shù)據(jù)應(yīng)用程序提供高吞吐量訪問(wèn)大型數(shù)據(jù)集的能力,它由Apache軟件基金會(huì)開(kāi)發(fā)和維護(hù),是Hadoop生態(tài)系統(tǒng)的重要組成部分,架構(gòu)HDFS采用主從架構(gòu),由以下組件組成,NameNode,NameNode是HDFS的中央服務(wù)器,負(fù)責(zé)管理文件系統(tǒng)元數(shù)據(jù),它存儲(chǔ)文件和目錄的...。
技術(shù)教程 2024-10-01 00:19:22
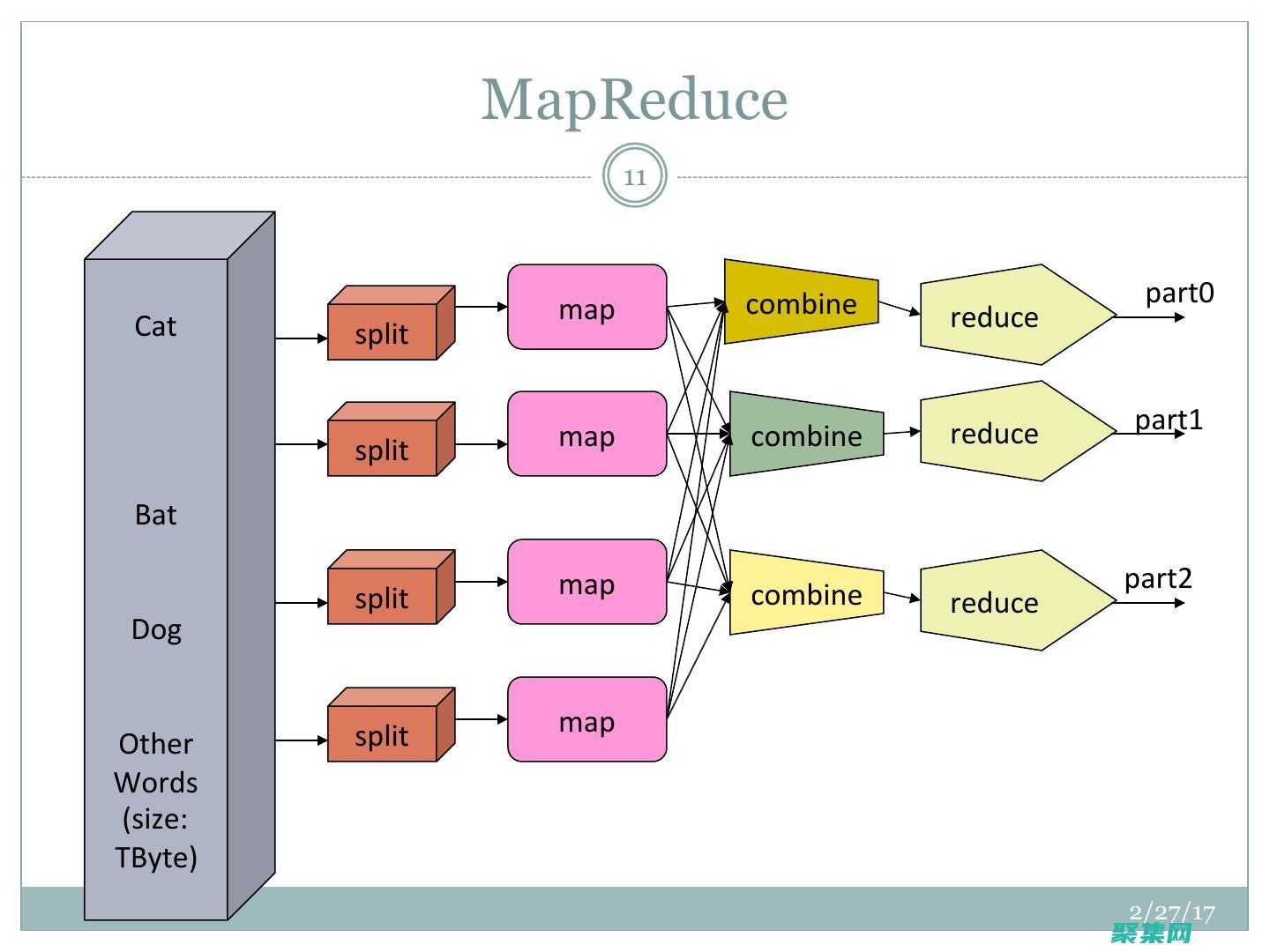 Hadoop 分布式文件系統(tǒng) (HDFS):綜合指南 (hadoop大數(shù)據(jù)開(kāi)發(fā)基礎(chǔ))
Hadoop 分布式文件系統(tǒng) (HDFS):綜合指南 (hadoop大數(shù)據(jù)開(kāi)發(fā)基礎(chǔ))
Hadoop分布式文件系統(tǒng),HDFS,綜合指南導(dǎo)言Hadoop分布式文件系統(tǒng),HDFS,是ApacheHadoop生態(tài)系統(tǒng)中一個(gè)基礎(chǔ)組件,它為大數(shù)據(jù)存儲(chǔ)和處理提供了可靠且可擴(kuò)展的基礎(chǔ)設(shè)施,本文將深入探討HDFS的體系結(jié)構(gòu)、組件、工作原理、優(yōu)點(diǎn)和局限性,并提供使用HDFS進(jìn)行大數(shù)據(jù)管理的實(shí)用指南,HDFS體系結(jié)構(gòu)HDFS采用主從架構(gòu),...。
技術(shù)教程 2024-10-01 00:16:11
 rhadoop: 打破 R 語(yǔ)言和 Hadoop 之間的界限,釋放大數(shù)據(jù)分析的全面潛力
rhadoop: 打破 R 語(yǔ)言和 Hadoop 之間的界限,釋放大數(shù)據(jù)分析的全面潛力
概述rhadoop是一個(gè)R語(yǔ)言包,它允許用戶無(wú)縫地訪問(wèn)和處理Hadoop分布式文件系統(tǒng),HDFS,中的大數(shù)據(jù)集,通過(guò)消除R與Hadoop之間的障礙,researchers和datascientists現(xiàn)在可以使用R語(yǔ)言的強(qiáng)大統(tǒng)計(jì)和繪圖功能來(lái)分析和可視化大數(shù)據(jù),優(yōu)點(diǎn)使用rhadoop有以下幾個(gè)優(yōu)點(diǎn),直接訪問(wèn)HDFS,直接從R語(yǔ)言讀取和寫(xiě)...。
最新資訊 2024-09-27 06:02:10
 rhadoop: 將 R 語(yǔ)言的強(qiáng)大功能擴(kuò)展到 Hadoop 生態(tài)系統(tǒng)
rhadoop: 將 R 語(yǔ)言的強(qiáng)大功能擴(kuò)展到 Hadoop 生態(tài)系統(tǒng)
簡(jiǎn)介RHadoop是一個(gè)R語(yǔ)言包,允許用戶將R語(yǔ)言的強(qiáng)大功能與Hadoop生態(tài)系統(tǒng)相結(jié)合,它通過(guò)提供R和Hadoop之間的接口,支持R腳本訪問(wèn)Hadoop文件系統(tǒng),HDFS,、MapReduce和YARN等Hadoop組件,借助RHadoop,R用戶可以利用R在數(shù)據(jù)科學(xué)、機(jī)器學(xué)習(xí)和統(tǒng)計(jì)分析方面的專業(yè)知識(shí)來(lái)處理和分析Hadoop中的海量...。
本站公告 2024-09-27 05:57:19
 rhadoop: Hadoop 分布式計(jì)算平臺(tái)與 R 統(tǒng)計(jì)語(yǔ)言的無(wú)縫融合
rhadoop: Hadoop 分布式計(jì)算平臺(tái)與 R 統(tǒng)計(jì)語(yǔ)言的無(wú)縫融合
引言rhadoop是一個(gè)強(qiáng)大的開(kāi)源軟件包,它無(wú)縫地將R統(tǒng)計(jì)語(yǔ)言與ApacheHadoop分布式計(jì)算平臺(tái)集成在一起,它使R用戶能夠利用Hadoop的強(qiáng)大計(jì)算能力,在大數(shù)據(jù)集上高效地處理、分析和可視化數(shù)據(jù),rhadoop彌合了R和Hadoop之間的差距,為數(shù)據(jù)科學(xué)家、統(tǒng)計(jì)學(xué)家和分析師提供了一個(gè)無(wú)與倫比的平臺(tái),可以在大數(shù)據(jù)環(huán)境中開(kāi)展高級(jí)分析...。
互聯(lián)網(wǎng)資訊 2024-09-27 05:54:39
 rhadoop: 簡(jiǎn)化 Hadoop 作業(yè)開(kāi)發(fā),提高 R 語(yǔ)言程序員的生產(chǎn)力
rhadoop: 簡(jiǎn)化 Hadoop 作業(yè)開(kāi)發(fā),提高 R 語(yǔ)言程序員的生產(chǎn)力
簡(jiǎn)介rhadoop是一個(gè)R語(yǔ)言包,它簡(jiǎn)化了Hadoop作業(yè)的開(kāi)發(fā),使R語(yǔ)言程序員能夠更高效地利用Hadoop的強(qiáng)大計(jì)算能力,它提供了一個(gè)直觀的接口,讓用戶能夠輕松地創(chuàng)建、提交和管理Hadoop作業(yè),而無(wú)需深入了解Hadoop的底層復(fù)雜性,特點(diǎn)rhadoop提供了許多關(guān)鍵特性,包括,Hadoop作業(yè)的簡(jiǎn)單創(chuàng)建和提交,用戶可以使用rhad...。
技術(shù)教程 2024-09-27 05:47:43
 rhadoop: 縮小 R 語(yǔ)言和 Hadoop 之間的差距,實(shí)現(xiàn)無(wú)縫數(shù)據(jù)交互
rhadoop: 縮小 R 語(yǔ)言和 Hadoop 之間的差距,實(shí)現(xiàn)無(wú)縫數(shù)據(jù)交互
引言R語(yǔ)言是一種用于統(tǒng)計(jì)計(jì)算和圖形表示的強(qiáng)大編程語(yǔ)言,Hadoop是一個(gè)分布式計(jì)算框架,用于處理大數(shù)據(jù)集,RHadoop是一個(gè)軟件包,它彌合了R語(yǔ)言和Hadoop之間的差距,允許無(wú)縫地將R語(yǔ)言用于Hadoop數(shù)據(jù)分析,RHadoop的優(yōu)點(diǎn)高效數(shù)據(jù)處理,Hadoop的分布式計(jì)算能力可并行處理海量數(shù)據(jù),顯著提高數(shù)據(jù)分析效率,無(wú)縫數(shù)據(jù)交互,...。
本站公告 2024-09-27 05:43:12
 rhadoop: 使用 R 語(yǔ)言進(jìn)行海量數(shù)據(jù)處理和機(jī)器學(xué)習(xí)
rhadoop: 使用 R 語(yǔ)言進(jìn)行海量數(shù)據(jù)處理和機(jī)器學(xué)習(xí)
簡(jiǎn)介rhadoop是一個(gè)R語(yǔ)言包,它使R能夠與Hadoop生態(tài)系統(tǒng)進(jìn)行交互,從而處理海量數(shù)據(jù)集,它通過(guò)Hadoop分布式文件系統(tǒng),HDFS,和MapReduce框架提供對(duì)基于Hadoop的數(shù)據(jù)源和計(jì)算資源的無(wú)縫訪問(wèn),結(jié)合R強(qiáng)大的統(tǒng)計(jì)和機(jī)器學(xué)習(xí)功能,rhadoop允許數(shù)據(jù)科學(xué)家和分析師高效地處理和分析大規(guī)模數(shù)據(jù),rhadoop的功能讀寫(xiě)...。
互聯(lián)網(wǎng)資訊 2024-09-27 05:40:31
 rhadoop: Hadoop 生態(tài)系統(tǒng)中面向 R 語(yǔ)言的便捷接口
rhadoop: Hadoop 生態(tài)系統(tǒng)中面向 R 語(yǔ)言的便捷接口
前言R語(yǔ)言是一種流行的統(tǒng)計(jì)編程語(yǔ)言,廣泛應(yīng)用于數(shù)據(jù)分析、機(jī)器學(xué)習(xí)和統(tǒng)計(jì)建模等領(lǐng)域,隨著大數(shù)據(jù)時(shí)代的到來(lái),Hadoop生態(tài)系統(tǒng)因其強(qiáng)大的分布式計(jì)算能力而受到廣泛關(guān)注,rhadoop是一個(gè)面向R語(yǔ)言的Hadoop接口,它允許R用戶輕松訪問(wèn)Hadoop生態(tài)系統(tǒng),從而實(shí)現(xiàn)大規(guī)模數(shù)據(jù)的分析和處理,rhadoop簡(jiǎn)介rhadoop是一個(gè)開(kāi)源R包,...。
本站公告 2024-09-27 05:37:15
 大數(shù)據(jù)編程高級(jí)課程:提升你的技能到下一個(gè)層次 (大數(shù)據(jù)編程高級(jí)教程)
大數(shù)據(jù)編程高級(jí)課程:提升你的技能到下一個(gè)層次 (大數(shù)據(jù)編程高級(jí)教程)
簡(jiǎn)介隨著大數(shù)據(jù)在各個(gè)行業(yè)變得越來(lái)越普遍,對(duì)具有大數(shù)據(jù)編程技能的專業(yè)人士的需求也在不斷增長(zhǎng),我們的高級(jí)大數(shù)據(jù)編程課程旨在為具有大數(shù)據(jù)基礎(chǔ)知識(shí)的個(gè)人提供高級(jí)技能,讓他們?cè)谠擃I(lǐng)域脫穎而出,課程目標(biāo)本課程旨在幫助學(xué)員,深入了解大數(shù)據(jù)框架和技術(shù),如ApacheHadoop、Spark和Hive掌握高級(jí)大數(shù)據(jù)處理技術(shù),包括數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)和可視...。
互聯(lián)網(wǎng)資訊 2024-09-27 02:06:59
 Java大數(shù)據(jù)編程:使用Hadoop、Spark和Flink處理海量數(shù)據(jù) (java大數(shù)據(jù)開(kāi)發(fā)是做什么的)
Java大數(shù)據(jù)編程:使用Hadoop、Spark和Flink處理海量數(shù)據(jù) (java大數(shù)據(jù)開(kāi)發(fā)是做什么的)
大數(shù)據(jù)簡(jiǎn)介大數(shù)據(jù)是指海量、復(fù)雜且快速生成的數(shù)據(jù)集,傳統(tǒng)的數(shù)據(jù)處理工具無(wú)法有效地處理它們,大數(shù)據(jù)具有以下特征,體量龐大,Volume,大數(shù)據(jù)數(shù)據(jù)集通常以TB或PB為單位,種類多樣,Variety,大數(shù)據(jù)包含多種數(shù)據(jù)類型,例如結(jié)構(gòu)化數(shù)據(jù),數(shù)據(jù)庫(kù)記錄,、非結(jié)構(gòu)化數(shù)據(jù),文本、圖像、視頻,和半結(jié)構(gòu)化數(shù)據(jù),XML、JSON,速度快,Velo...。
本站公告 2024-09-12 05:52:27
 大數(shù)據(jù)數(shù)據(jù)庫(kù)測(cè)試:處理海量數(shù)據(jù)的測(cè)試策略和技術(shù) (大數(shù)據(jù)數(shù)據(jù)庫(kù)有哪些開(kāi)源)
大數(shù)據(jù)數(shù)據(jù)庫(kù)測(cè)試:處理海量數(shù)據(jù)的測(cè)試策略和技術(shù) (大數(shù)據(jù)數(shù)據(jù)庫(kù)有哪些開(kāi)源)
簡(jiǎn)介隨著大數(shù)據(jù)時(shí)代的到來(lái),傳統(tǒng)數(shù)據(jù)庫(kù)無(wú)法滿足海量數(shù)據(jù)的存儲(chǔ)和處理需求,于是出現(xiàn)了專門(mén)為大數(shù)據(jù)而設(shè)計(jì)的數(shù)據(jù)庫(kù),如Hadoop、MongoDB和Cassandra,這些數(shù)據(jù)庫(kù)具有可擴(kuò)展性高、并發(fā)處理能力強(qiáng)、容錯(cuò)性好等特點(diǎn),但也給數(shù)據(jù)庫(kù)測(cè)試帶來(lái)了新的挑戰(zhàn),大數(shù)據(jù)數(shù)據(jù)庫(kù)測(cè)試的挑戰(zhàn)大數(shù)據(jù)數(shù)據(jù)庫(kù)測(cè)試面臨以下挑戰(zhàn),數(shù)據(jù)量龐大,大數(shù)據(jù)數(shù)據(jù)庫(kù)通常存儲(chǔ)著...。
本站公告 2024-09-09 12:30:06
 Java 大數(shù)據(jù)分析:利用 Hadoop、Spark 和 Hive 駕馭海量數(shù)據(jù) (java大數(shù)據(jù)開(kāi)發(fā)是做什么的)
Java 大數(shù)據(jù)分析:利用 Hadoop、Spark 和 Hive 駕馭海量數(shù)據(jù) (java大數(shù)據(jù)開(kāi)發(fā)是做什么的)
引言在大數(shù)據(jù)時(shí)代,企業(yè)需要處理和分析海量數(shù)據(jù),從中提取有價(jià)值的信息以做出明智的決策,Java是一種強(qiáng)大的編程語(yǔ)言,可用于構(gòu)建大數(shù)據(jù)分析解決方案,本文將介紹利用Hadoop、Spark和Hive等技術(shù),使用Java進(jìn)行大數(shù)據(jù)分析的基礎(chǔ)知識(shí),Hadoop基礎(chǔ)Hadoop是一個(gè)分布式計(jì)算框架,旨在處理海量數(shù)據(jù),它包括以下主要組件,HDFS,...。
互聯(lián)網(wǎng)資訊 2024-09-06 09:56:35