(換膚)
語言:

 自然語言處理:處理文本數(shù)據(jù),執(zhí)行文本分類、情感分析和機器翻譯。(自然語言處理包括哪些內容)
自然語言處理:處理文本數(shù)據(jù),執(zhí)行文本分類、情感分析和機器翻譯。(自然語言處理包括哪些內容)
自然語言處理,NLP,是一種人工智能,AI,分支,它允許計算機理解、解釋和生成人類語言,NLP的內容NLP涉及多種技術,用于處理文本數(shù)據(jù)并執(zhí)行各種任務,包括,文本分類文本分類涉及將文本文檔分配到預定義類別或標簽的過程,例如,我們可以將電子郵件分類為,垃圾郵件,或,非垃圾郵件,,或者將新聞文章分類為,體育,或,政治,情感分析情感分析旨...。
技術教程 2024-10-01 06:22:35
 數(shù)據(jù)參量化對數(shù)據(jù)可視化的影響:提升溝通和洞察 (數(shù)據(jù)參量化對象有哪些)
數(shù)據(jù)參量化對數(shù)據(jù)可視化的影響:提升溝通和洞察 (數(shù)據(jù)參量化對象有哪些)
數(shù)據(jù)參量化是一個將定性數(shù)據(jù)轉換為定量數(shù)據(jù)的過程,以便能夠對其進行量化分析和可視化,它對于提高數(shù)據(jù)可視化的溝通和洞察至關重要,2.更深的洞察數(shù)據(jù)參量化使我們能夠量化和分析定性數(shù)據(jù),從中提取有價值的洞察,通過應用統(tǒng)計技術、機器學習和自然語言處理,我們可以識別模式、趨勢和關系,這些關系在定性數(shù)據(jù)中可能無法明顯看出,3.更好的決策更好的溝通和...。
技術教程 2024-09-30 05:01:53
 Java畢業(yè)設計:探索人工智能在金融科技行業(yè)的應用 (Java畢業(yè)設計題目)
Java畢業(yè)設計:探索人工智能在金融科技行業(yè)的應用 (Java畢業(yè)設計題目)
前言隨著人工智能,AI,技術的飛速發(fā)展,其在金融科技行業(yè)的應用也越發(fā)廣泛,AI的特性,如機器學習、自然語言處理和數(shù)據(jù)分析,為金融科技行業(yè)帶來了新的機遇和挑戰(zhàn),本Java畢業(yè)設計旨在探索AI在金融科技領域的應用,并開發(fā)一款基于Java的智能金融科技應用,研究背景金融科技行業(yè)正在經(jīng)歷一場數(shù)字化轉型,AI技術已成為該轉型進程中的重要驅動力,...。
最新資訊 2024-09-30 01:58:03
 Java畢業(yè)設計:開發(fā)一個基于Android的移動應用程序,融合人工智能技術 (JAVA畢業(yè)設計)
Java畢業(yè)設計:開發(fā)一個基于Android的移動應用程序,融合人工智能技術 (JAVA畢業(yè)設計)
引言人工智能,AI,技術正在飛速發(fā)展,并被廣泛應用于各個領域,包括移動應用程序開發(fā),Android平臺憑借其龐大的用戶群體和豐富的開發(fā)環(huán)境,成為開發(fā)AI驅動型應用程序的理想平臺,設計目標本畢業(yè)設計旨在開發(fā)一款基于Android的移動應用程序,充分利用AI技術,為用戶提供智能化和個性化的體驗,該應用程序將融合以下AI技術,自然語言處理,...。
技術教程 2024-09-30 01:46:37
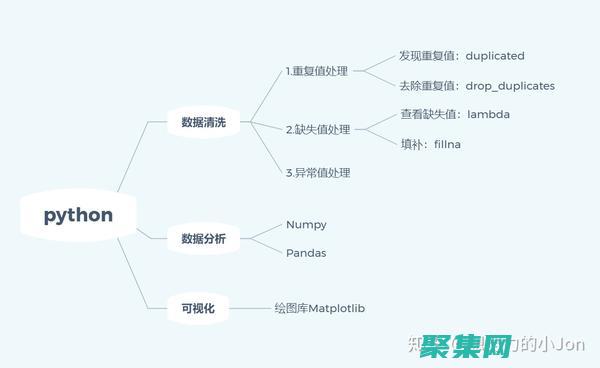 剖析Python split函數(shù):揭開分詞背后的技術細節(jié) (剖析的拼音)
剖析Python split函數(shù):揭開分詞背后的技術細節(jié) (剖析的拼音)
引言分詞是自然語言處理中一項基本任務,它將文本分解為更小的、有意義的單位,Python提供了幾個用于分詞的函數(shù),其中`split,`函數(shù)是最常用的函數(shù)之一,本文將對Python`split,`函數(shù)進行深入剖析,揭開其分詞背后的技術細節(jié),split函數(shù)的用法Python`split,`函數(shù)的用法非常簡單,它接受一個字符串作為參數(shù),...。
互聯(lián)網(wǎng)資訊 2024-09-28 18:00:04
 Python split函數(shù)揭秘:揭開分詞的強大功能 (python怎么讀)
Python split函數(shù)揭秘:揭開分詞的強大功能 (python怎么讀)
前言分詞是自然語言處理,NLP,中的一項重要任務,它將一串文本分解成一個個單獨的單詞或符號,以便進行進一步的處理,Python提供了強大的split,函數(shù),用于執(zhí)行分詞操作,本文將深入探索split,函數(shù),揭示其功能和使用方法,幫助你充分利用其分詞能力,split,函數(shù)的語法split,函數(shù)的語法如下,```pythonstr...。
技術教程 2024-09-28 17:48:44
 PDF 解析在文檔管理中的應用:促進自動化和提高效率 (pdf 文件解析)
PDF 解析在文檔管理中的應用:促進自動化和提高效率 (pdf 文件解析)
在現(xiàn)代數(shù)字化環(huán)境中,文檔管理已成為各種規(guī)模企業(yè)的重要組成部分,傳統(tǒng)的人工文檔處理方法效率低下且容易出錯,PDF解析技術通過自動化文檔處理流程,為文檔管理帶來了革命性的變化,從而提高了效率和準確性,什么是PDF解析,PDF解析涉及從PDF文檔中提取結構化和非結構化數(shù)據(jù)的過程,它利用光學字符識別,OCR,和自然語言處理,NLP,技術,將掃...。
技術教程 2024-09-27 11:00:30
 釋放您寫作的潛力:使用 Filter2 克服內容寫作障礙 (釋放您寫作的興趣英語)
釋放您寫作的潛力:使用 Filter2 克服內容寫作障礙 (釋放您寫作的興趣英語)
內容寫作是一項技能,既需要天賦,也需要技巧,對于許多人來說,最困難的部分之一就是克服寫作阻塞,但是有了Filter2,您可以釋放您的寫作潛力并輕松克服這些障礙,F(xiàn)ilter2是一款強大的人工智能工具,可幫助您生成高質量的內容摘要、標題和文章大綱,它使用先進的自然語言處理技術來理解您的文本并為您提供有用的見解,使用Filter2克服內容...。
互聯(lián)網(wǎng)資訊 2024-09-25 06:55:38
 使用 AI 技術提升內容寫作:利用 Filter2突破創(chuàng)意界限 (使用ai技術詐騙)
使用 AI 技術提升內容寫作:利用 Filter2突破創(chuàng)意界限 (使用ai技術詐騙)
在當今快節(jié)奏的數(shù)字環(huán)境中,創(chuàng)建引人入勝且有效的內容至關重要,人工智能,AI,技術已成為內容創(chuàng)作者的有力工具,能夠提高效率、增強創(chuàng)造力并產生更優(yōu)質的內容,IntroducingFilter2,YourAIWritingAssistantFilter2是一項先進的AI寫作助手,旨在幫助您突破創(chuàng)意界限并提升您的內容寫作技能,借助自然語言處理...。
最新資訊 2024-09-25 06:39:06
 標簽云的未來:從簡單的導航到先進的語義分析 (標簽云是什么)
標簽云的未來:從簡單的導航到先進的語義分析 (標簽云是什么)
標簽云是什么,標簽云是一種可視化工具,它以不同大小和顏色的字體顯示一組關鍵字或標簽,標簽的大小和顏色通常與詞頻相關,詞頻較高的標簽會以較大的字體和較深的顏色顯示,標簽云通常用于,幫助用戶瀏覽網(wǎng)站或文檔顯示特定主題或話題的熱門術語用于數(shù)據(jù)可視化和探索標簽云的未來隨著自然語言處理,NLP,和機器學習,ML,的發(fā)展,標簽云在未來將得到廣泛的...。
技術教程 2024-09-24 06:24:22
 提供了分詞后處理工具,使分詞結果更加準確和有用。(分詞后面加什么詞)
提供了分詞后處理工具,使分詞結果更加準確和有用。(分詞后面加什么詞)
分詞是自然語言處理,NLP,中一項基本任務,它將文本分解為單獨的單詞或詞組,稱為詞素,分詞的結果對于許多NLP任務至關重要,例如信息檢索、情感分析和機器翻譯,原始分詞的結果并不總是準確或有用的,為了解決這個問題,已經(jīng)開發(fā)了各種分詞后處理技術,這些技術可以提高分詞結果的準確性,使其更適合特定應用,分詞后處理技術詞性標注,將詞素標記為名詞...。
本站公告 2024-09-23 23:40:32
 易于使用和集成,只需幾行代碼即可完成中文文本分詞。(易于使用的英文)
易于使用和集成,只需幾行代碼即可完成中文文本分詞。(易于使用的英文)
中文文本分詞是將一段中文文本拆分成一個個單詞或短語的過程,它在自然語言處理中非常重要,因為它可以幫助我們理解文本的含義,進行文本分類和檢索,傳統(tǒng)上,中文文本分詞是一項復雜的任務,需要使用復雜的算法和詞典,隨著機器學習和深度學習技術的進步,現(xiàn)在我們可以使用更簡單的方法來進行中文文本分詞,本文將介紹一種簡單易用的中文文本分詞方法,該方法只...。
技術教程 2024-09-23 23:39:00
 支持多種分詞算法,提供了靈活性。(分詞能做什么)
支持多種分詞算法,提供了靈活性。(分詞能做什么)
分詞是一種自然語言處理技術,它將一段連續(xù)的文本分解成一個個獨立的詞語,分詞對于后續(xù)的自然語言處理任務,例如詞性標注、句法分析、語義分析等,有著至關重要的作用,不同的分詞算法有不同的特點和優(yōu)勢,因此不同的應用場景需要選擇合適的分詞算法,例如,基于詞典的分詞算法速度快,但是對于新詞和罕見詞的識別能力較弱;基于統(tǒng)計的分詞算法識別新詞和罕見詞...。
本站公告 2024-09-23 23:36:47
 與流行的 NLP 庫集成,如 NLTK、spaCy、Scikit-Learn 等。(與流行的云同樣調弦的曲子)
與流行的 NLP 庫集成,如 NLTK、spaCy、Scikit-Learn 等。(與流行的云同樣調弦的曲子)
自然語言處理,NLP,是一門機器學習子領域,它專注于使計算機能夠理解和處理人類語言,NLP在各種應用程序中都有應用,例如文本分類、文本生成、機器翻譯和問答,有許多流行的NLP庫可供使用,例如NLTK、spaCy和Scikit,Learn,這些庫提供了各種功能,可幫助您開發(fā)NLP應用程序,例如,NLTK提供了一套用于自然語言處理任務的工...。
最新資訊 2024-09-23 23:35:45
 自定義詞典和停用詞表,以提高分詞的準確性和效率。(自定義詞典下載)
自定義詞典和停用詞表,以提高分詞的準確性和效率。(自定義詞典下載)
分詞是自然語言處理中的一項基本任務,它將文本分解成更小的語義單位,詞語,分詞的準確性和效率對于后續(xù)的自然語言處理任務至關重要,例如命名實體識別、文本分類和機器翻譯,自定義詞典和停用詞表是提高分詞準確性和效率的有效方法,自定義詞典包含特定領域或應用的詞匯,這些詞匯可能未包含在默認詞典中,停用詞表包含常見且意義不大的詞語,例如介詞、連詞...。
最新資訊 2024-09-23 23:32:24
 探索 Tokenize:自然語言處理中文本分詞的全面指南 (探索同義詞替換)
探索 Tokenize:自然語言處理中文本分詞的全面指南 (探索同義詞替換)
分詞是自然語言處理,NLP,的一項基本任務,它涉及將文本分解成較小的有意義的單位,稱為標記,對于中文文本而言,分詞是一個尤其重要的步驟,因為它可以幫助我們理解文本的含義并進行進一步的處理,Tokenize庫是一個功能強大的Python庫,可用于對中文文本進行分詞,它提供了各種功能,使分詞過程高效且準確,本文將提供一份Tokenize庫...。
互聯(lián)網(wǎng)資訊 2024-09-23 23:29:20
 使用 Tokenize 加速自然語言處理管道 (使用Tor瀏覽器違法嗎)
使用 Tokenize 加速自然語言處理管道 (使用Tor瀏覽器違法嗎)
使用Tokenize加速自然語言處理管道導言自然語言處理,NLP,是一項熱門的研究領域,應用程序廣泛,NLP管道通常計算密集且耗時,Tokenize是一個輕量級的Python庫,旨在通過加速標記化過程來加快NLP管道,本文將探討Tokenize的功能、優(yōu)勢和使用案例,并提供一個示例來展示其如何加速NLP管道,Tokenize的功能To...。
最新資訊 2024-09-23 23:23:42
 利用 Tokenize 優(yōu)化文本特征提取和表示 (利用token進行登錄)
利用 Tokenize 優(yōu)化文本特征提取和表示 (利用token進行登錄)
簡介文本數(shù)據(jù)在機器學習和自然語言處理任務中普遍存在,從文本中提取有意義的特征對于開發(fā)有效的機器學習模型至關重要,Tokenize是將文本分解為更小單元,稱為令牌,的一種技術,它可以極大地提高文本特征提取和表示的效率,Token的類型令牌可以有不同類型,包括,單詞令牌,由空格或其他分隔符分隔的文本中的單個單詞,n元組令牌,相鄰單詞序列中...。
技術教程 2024-09-23 23:22:36
 Tokenize 101:面向初學者的文本分詞指南 (tokenim錢包官網(wǎng)下載)
Tokenize 101:面向初學者的文本分詞指南 (tokenim錢包官網(wǎng)下載)
什么是分詞,分詞是將一段文本分解成更小單位,稱為詞素,的過程,這些詞素可以用來表示文本的含義,并進行進一步的處理,如詞頻分析或機器學習,為什么分詞很重要,分詞對于以下任務至關重要,自然語言處理,NLP,信息檢索文本挖掘機器學習分詞的不同類型有不同的分詞類型,取決于要執(zhí)行的任務和需要達到的精度水平,最常見的分詞類型包括,li>,精度...。
本站公告 2024-09-23 23:21:27
 揭開 Tokenize 的面紗:探索文本分詞的藝術 (揭開童年父母經(jīng)典騙術)
揭開 Tokenize 的面紗:探索文本分詞的藝術 (揭開童年父母經(jīng)典騙術)
什么是文本分詞,文本分詞是指將文本分解成更小的、獨立的單位的過程,稱為,詞素,token,這些詞素可以是單詞、標點符號、數(shù)字或其他有意義的文本片段,分詞是自然語言處理,NLP,中的一項基本任務,對于機器理解文本至關重要,Tokenize的作用文本分詞有許多用途,包括,詞頻分析,確定文本中單詞出現(xiàn)的頻率詞干提取,移除單詞的詞綴,提取...。
互聯(lián)網(wǎng)資訊 2024-09-23 23:20:06
 Tokenize:自然語言處理領域的文本分詞利器 (tokenizer)
Tokenize:自然語言處理領域的文本分詞利器 (tokenizer)
在自然語言處理,NLP,領域,分詞是將文本分解為單個詞或符號的基本過程,Tokenize是一種用于此目的的強大工具,它使NLP應用程序能夠有效地處理文本數(shù)據(jù),本文將深入探討Tokenize,解釋其功能、優(yōu)點和應用,什么是Tokenize,Tokenize是一種算法,它將一段文本輸入并輸出一個詞或符號列表,稱為標記,這些標記代表文本中...。
本站公告 2024-09-23 23:18:36
 使用 Tokenize 對海量文本數(shù)據(jù)進行高效預處理 (使用Tor瀏覽器違法嗎)
使用 Tokenize 對海量文本數(shù)據(jù)進行高效預處理 (使用Tor瀏覽器違法嗎)
在現(xiàn)代數(shù)據(jù)科學中,處理海量文本數(shù)據(jù)已變得越來越普遍,從社交媒體分析到自然語言處理,文本數(shù)據(jù)在各種領域都發(fā)揮著至關重要的作用,為了有效地分析文本數(shù)據(jù),將其預處理成可供機器學習算法或其他分析工具使用的格式至關重要,預處理步驟包括去除冗余信息、標準化文本以及將文本分解成更小的單位,稱為標記,Tokenize簡介Tokenize是一項用于文本...。
互聯(lián)網(wǎng)資訊 2024-09-23 23:17:46
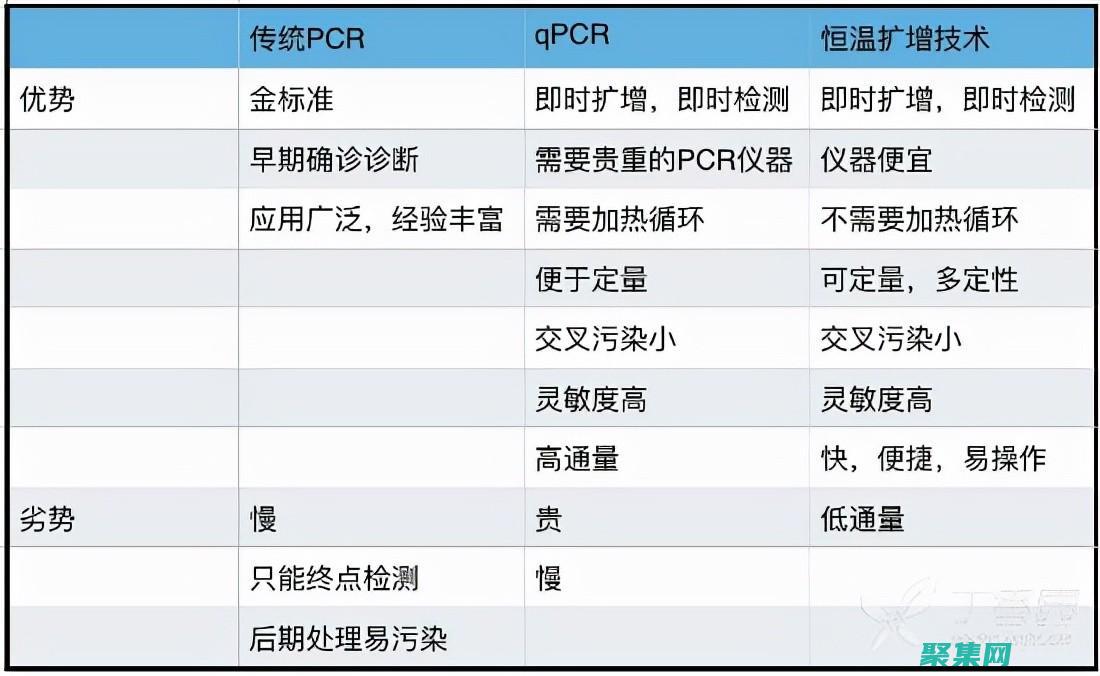 PCRE 與人工智能:在自然語言處理和機器學習中利用正則表達式 (pcre和pcre-devel)
PCRE 與人工智能:在自然語言處理和機器學習中利用正則表達式 (pcre和pcre-devel)
簡介正則表達式,PCRE,是一種強大的語言,用于在字符串和其他文本數(shù)據(jù)中查找、替換和驗證模式,近年來,PCRE已成為自然語言處理,NLP,和機器學習,ML,應用中必不可少的一部分,PCRE是PCRE和PCRE,devel兩個庫的集合,PCRE,devel是PCRE的一個增強版本,具有額外的功能,例如Unicode支持和JIT編譯,自然...。
技術教程 2024-09-17 01:58:58
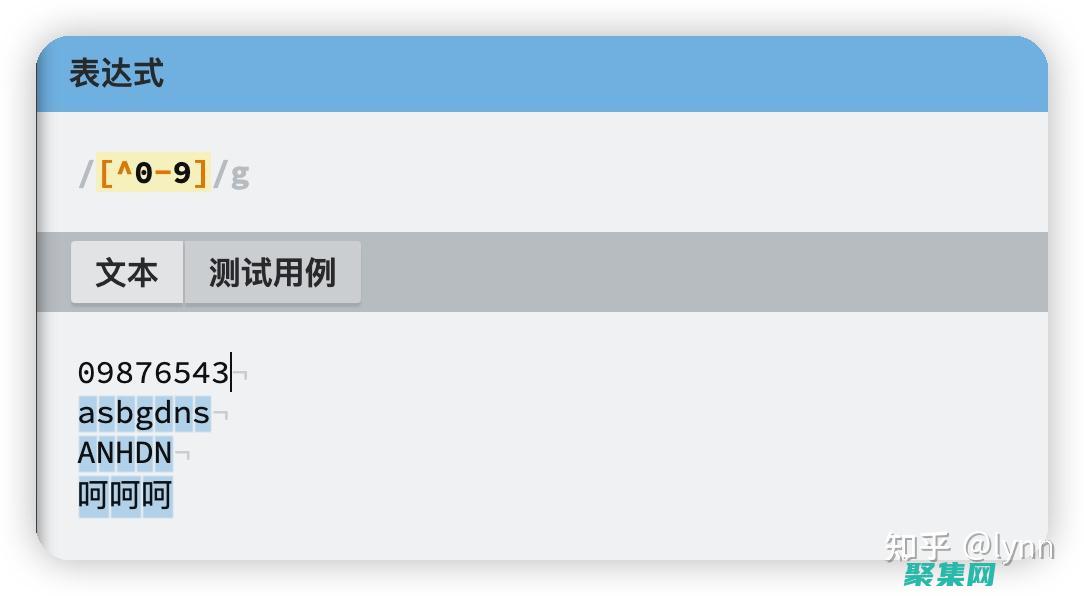 發(fā)現(xiàn)正則表達式世界的強大:從基礎到高級 (發(fā)現(xiàn)正則表達式怎么寫)
發(fā)現(xiàn)正則表達式世界的強大:從基礎到高級 (發(fā)現(xiàn)正則表達式怎么寫)
簡介正則表達式,regex,是一種強大的文本模式匹配語言,用于在文本中查找、替換或驗證特定模式,它們廣泛應用于各種領域,包括編程、文本處理、數(shù)據(jù)驗證和自然語言處理,基礎知識元字符正則表達式使用元字符來匹配特定字符或字符類,常見的元字符包括,匹配任何字符匹配前面的表達式零次或多次匹配前面的表達式一次或多次匹配前面的表達式零次或一次匹配方...。
互聯(lián)網(wǎng)資訊 2024-09-16 16:26:53
 斯坦福解析器在商業(yè)和工業(yè)中的應用:提高效率和推動創(chuàng)新 (斯坦福解剖網(wǎng)易公開課)
斯坦福解析器在商業(yè)和工業(yè)中的應用:提高效率和推動創(chuàng)新 (斯坦福解剖網(wǎng)易公開課)
簡介斯坦福解析器是一個強大的自然語言處理,NLP,工具,它能夠分析文本并提取有意義的信息,近年來,它在商業(yè)和工業(yè)領域獲得了廣泛的應用,為各種任務帶來了許多好處,包括提高效率、推動創(chuàng)新和改善客戶體驗,商業(yè)中的應用數(shù)據(jù)挖掘和分析斯坦福解析器可以用于從非結構化文本數(shù)據(jù)中提取見解,這對于分析市場趨勢、客戶反饋和社交媒體數(shù)據(jù)非常有用,通過識別模...。
本站公告 2024-09-16 13:47:46
 斯坦福解析器的最佳實踐:優(yōu)化使用并獲得最大收益的技巧 (斯坦福詞條)
斯坦福解析器的最佳實踐:優(yōu)化使用并獲得最大收益的技巧 (斯坦福詞條)
簡介斯坦福解析器是自然語言處理領域備受推崇的工具,可用于詞法分析、句法分析和語義分析等各種任務,通過遵循最佳實踐,您可以優(yōu)化解析器使用,最大程度地提高其性能和準確性,優(yōu)化詞法分析使用定制詞典,添加特定領域的術語和縮寫到詞典中,以提高解析器識別和標記這些詞的能力,啟用分詞,允許解析器將單詞劃分為更小單位,例如詞根和詞綴,以提高準確性,優(yōu)...。
互聯(lián)網(wǎng)資訊 2024-09-16 13:46:52
 斯坦福解析器與其他自然語言處理工具的比較:優(yōu)勢、局限性和最佳用例 (斯坦福解剖網(wǎng)易公開課)
斯坦福解析器與其他自然語言處理工具的比較:優(yōu)勢、局限性和最佳用例 (斯坦福解剖網(wǎng)易公開課)
斯坦福解析器是斯坦福大學自然語言處理組開發(fā)的一款流行的自然語言處理,NLP,工具包,它以其強大的解析功能而聞名,常用于各種NLP任務,如句法分析、依存關系分析和命名實體識別,除了斯坦福解析器之外,還有許多其他NLP工具可供選擇,這些工具在功能、性能和適用性方面各不相同,在選擇NLP工具時,了解這些工具的優(yōu)點、缺點和最佳用例至關重要,斯...。
互聯(lián)網(wǎng)資訊 2024-09-16 13:45:29
 斯坦福解析器的未來:新功能、增強功能和應用程序 (斯坦福解剖網(wǎng)易公開課)
斯坦福解析器的未來:新功能、增強功能和應用程序 (斯坦福解剖網(wǎng)易公開課)
斯坦福解析器是使用最廣泛的自然語言處理,NLP,工具包之一,由斯坦福大學開發(fā),它是一種強大的工具,用于執(zhí)行各種NLP任務,包括詞法分析、句法分析和語義分析,新功能斯坦福解析器的最新版本引入了多項新功能,包括,新的詞嵌入,詞嵌入是用于表示單詞含義的向量,斯坦福解析器現(xiàn)在包含來自GoogleNews和Wikipedia的預先訓練好的詞嵌入...。
本站公告 2024-09-16 13:44:19
 斯坦福解析器:自然語言處理學生和研究人員的重要工具 (斯坦福詞條)
斯坦福解析器:自然語言處理學生和研究人員的重要工具 (斯坦福詞條)
簡介斯坦福解析器是一個廣泛用于自然語言處理,NLP,的開放源碼語法解析器,它由斯坦福大學自然語言處理組開發(fā),于2003年首次發(fā)布,自那時以來,它已成為NLP領域最流行的解析器之一,并被廣泛用于各種NLP任務,包括,句法分析詞性標注依存關系分析語義角色標記斯坦福解析器以其準確性、效率和易用性而聞名,它使用基于轉換語法模型的統(tǒng)計方法進行解...。
本站公告 2024-09-16 13:42:39
 揭秘斯坦福解析器的內幕:算法、模型和訓練數(shù)據(jù) (斯坦福pi)
揭秘斯坦福解析器的內幕:算法、模型和訓練數(shù)據(jù) (斯坦福pi)
斯坦福解析器是一個自然語言處理,NLP,工具,用于對文本進行語法分析,它由斯坦福大學的研究人員開發(fā),是當今最先進的解析器之一,在本篇文章中,我們將深入了解斯坦福解析器的內部機制,包括它使用的算法、模型和訓練數(shù)據(jù),算法斯坦福解析器使用動態(tài)規(guī)劃算法來對文本進行解析,動態(tài)規(guī)劃是一種分治方法,將問題分解為較小的子問題,然后逐步解決這些子問題,...。
本站公告 2024-09-16 13:41:27